Pandas
La Data Science avec Pandas
Pandas permet de traiter et d'analyser de gros jeux de données en utilisant le langage Python.
Commencer
Aconda et Jupyter notebooks
Mon environnement de développement
Prérequis avant de commencer
J'utilise les Jupyter Notebooks lancés depuis la distribution Anaconda.
Les Jupyter Notebookss
Coder avec Pandas de manière interactive
Un Jupytern Notebook est un fichier au format ipynb.
Le code est écrit dans des cellules qui peuvent être exécutées individuellement.
Les bibliothèques externes
Importation des bibliothèques externes pandas, numpy, pyplot de matplotlib et seaborn
Par habitude, on utilise les acronymes pd pour pandas, np pour numpy, plt pour pyplot et sns pour seaborn.
On va aussi utiliser la bibliothèque interne warnings.
-
>>> import pandas as pd >>> import numpy as np >>> import matplotlib.pyplot as plt >>> import seaborn as sns >>> import warnings
Configuration
Warnings et options d'affichage
Warnings
L'option FutureWarning permet d'ignorer les avertissements pour de futures modifications de Pandas.
-
>>> warnings.simplefilter(action='ignore', category=FutureWarning)
Affichage des colonnes et lignes
Les méthodes set_option et reset_option permettent de faire varier le nombre de lignes et de colonnes affichées par défaut.
-
>>> pd.set_option('display.max_columns', None) >>> pd.set_option('display.max_rows', None) >>> pd.reset_option("display.max_columns") >>> pd.reset_option("display.max_rows")
Création d'un dataframe
Un dataframe est l'élément de base de Pandas.
Un dataframe est un tableau à 2 dimensions avec des noms de colonnes (column names) et des identifiants de lignes (row index).
C'est une instance de la classe DataFrame Pandas.
Création à partir d'un dictionnaire
Chaque couple clé valeurs du dicionnaire deviendra une colonne du dataframe.
Dataframe sans indexs prédéfinis
Dans l'exemple suivant, on crée le dataframe df à partir d'un dictionnaire contenant les clés age et genre. Les index sont numérotés automatiquement de 0 à 3. Dans un Jupyte Notebook, la fonction display permet d'afficher le dataframe.
-
>>> df = pd.DataFrame({'age': [12, 11, 12], 'genre': ['M', 'F', 'M']}) >>> display(df)
age genre 0 12 M 1 11 F 2 12 M
Dataframe avec des indexs définis par l'utilisateur
Dans l'exemple suivant, on crée le dataframe df_with_names à partir du même dictionnaire mais avec des indexs définis grâce au paramètre index.
-
>>> df_with_names = pd.DataFrame({'age': [12, 11, 12], 'genre': ['M', 'F', 'M']}, index=['Paul', 'Anne', 'Jean']) >>> display(df_with_names)
age genre Paul 12 M Anne 11 F Jean 12 M
Création à partir d'un fichier csv
Dans l'exemple suivant, on crée le dataframe df en utilisant la méthode read_csv qui permet de lire le fichier mon_datset.csv.
-
>>> df_csv = pd.read_csv('mon_dataset.csv', sep=';')
Description
Caracatéristiques, taille, colonnes
Afficher les 1eres lignes
Dans l'exemple suivant, la méthode head permet d'afficher les 2 premières lignes de df
-
>>> df.head(2)
age genre 0 12 M 1 11 F
Résumé
Dans l'exemple suivant, la méthode info permet d'afficher un bref résumé des données contenues dans le dataframe df.
-
>>> df.info() <class 'pandas.core.frame.DataFrame'> RangeIndex: 3 entries, 0 to 2 Data columns (total 2 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 age 3 non-null int64 1 genre 3 non-null object dtypes: int64(1), object(1) memory usage: 176.0+ bytes
Statistiques
Dans l'exemple suivant, la méthode describe permet d'afficher un datraframe avec les statistiques de la colonne numérique age de df.
count: Nombre de valeurs non nulles,
mean: Moyenne,
std: Écart-type,
min: Valeur minimale,
25%: Premier quartile (Q1) ou 25e percentile,
50%: Deuxième quartile (Q2) ou médiane,
75%: Troisième quartile (Q3) ou 75e percentile,
max: Valeur maximale.
-
>>> df.describe()
age count 3.000000 mean 11.666667 std 0.577350 min 11.000000 25% 11.500000 50% 12.000000 75% 12.000000 max 12.000000
Types
Dans l'exemple suivant, la propriété dtypes permet d'afficher une série avec le type de données de chaque colonne du dataframe df.
-
>>> df.dtypes age int64 genre object dtype: object
Taille
Dans l'exemple suivant, la propriété shape permet de récupérer un tuple avec le nombre de lignes et de colonnes.
-
>>> df.shape (3, 2)
Lister les noms de colonnes
Voici 2 techniques différentes
Avec la fonction list
Dans l'exemple suivant, nous affichons la liste des noms de colonnes de df.
-
>>> list(df) ['age', 'genre']
Avec la propriété colums
Dans l'exemple suivant, nous affichons un index avec la liste des noms de colonnes de df.
-
>>> print(df.columns) Index(['age', 'genre'], dtype='object')
Compter les lignes ou les valeurs uniques
La méthode value_counts compte les lignes uniques dans le dataframe ou les valeurs uniques dans une colonne et renvoie le résultat dans une une série.
Dans tout le dataframe
Dans l'exemple suivant, nous comptons les lignes uniques.
-
>>> df.value_counts() age genre 12 M 2 11 F 1 Name: count, dtype: int64
Dans une colonne
Dans l'exemple suivant, nous comptons les valeurs uniques de la colonne age.
-
>>> df['age'].value_counts() age 12 2 11 1 Name: age, dtype: int64
Trouver les valeurs uniques d'une colonne
Avec la méthode unique
Dans tout le dataframe
Dans l'exemple suivant, nous comptons les lignes uniques.
-
>>> df['age'].unique() array([12, 11], dtype=int64)
Sélection
Sélectionner les éléments d'un dataframe
Sélectionner une colonne
Voici 3 techniques différentes
Avec le nom de la colonne entre crochets
Dans l'exemple suivant, on sélectionne la colonne age.
-
>>> df['age'] 0 12 1 11 2 12 Name: age, dtype: int64
Avec un point suivi du nom de la colonne
Dans l'exemple suivant, on sélectionne encore la colonne age.
-
>>> df.age 0 12 1 11 2 12 Name: age, dtype: int64
Avec l'index de la colonne et la méthode iloc
Dans l'exemple suivant, on sélectionne la 2e colonne.
-
>>> df.iloc[:, 1] 0 M 1 F 2 M Name: genre, dtype: object
Sélectionner par type
Dans l'exemple suivant, la méthode select_dtypes permet de sélectionner les colones contenant des nombres.
-
>>> df_num = df.select_dtypes(include=['number']) >>> df_numage 0 12 1 11 2 12
Modifications
Techniques utiles pour nettoyer et manipuler les dataframes
Insérer une ligne au début (à l'index 0)
Voici 3 techniques différentes
Avec loc[-1]
On insère la liste ['M', 13] en premier.
-
>>> df.loc[-1] = [13, 'M'] >>> df.index = df.index + 1 >>> df.sort_index(inplace=True) >>> display(df)
Avec loc[0]
On insère la liste ['M', 13] en deuxième.
-
>>> df.index = df.index + 1 >>> df.loc[0] = [13, 'M'] >>> df.sort_index(inplace=True)
Avec la méthode concat
On crée un nouveau un nouveau dataframe df2 avec la liste ['M', 13] d'abord, puis on concatène.
-
>>> df2 = pd.DataFrame(columns=df.columns, data=[[13, 'M']]) >>> df = pd.concat([df2, df], ignore_index=True) >>> display(df)
age genre 0 13 M 1 12 M 2 11 F 3 12 M
Supprimer une ligne
Avec la méthode drop
Supprimer une ligne en la sélectionnant par son index
On supprime la première ligne d'index 0. La méthode reset_index permet de renuméroter automatiquement les indexs.
-
>>> df.drop([0], inplace=True) >>> df.reset_index(inplace=True, drop=True)
Supprimer une ligne en fonction de la valeur d'une colonne
Une autre manière de le faire, c'est de sélectionner les autres lignes qui n'ont pas pour valeur 13 dans la colonne age.
-
>>> df = df[df.age != 13] >>> df.reset_index(inplace=True, drop=True) >>> display(df)
age genre 0 12 M 1 11 F 2 12 M
Supprimer une colonne
Avec la méthode drop
Supprimer une colonne en la sélectionnant par son nom
On supprime la colonne genre.
-
>>> df.drop(['genre'], axis=1, inplace=True) >>> dfage 0 12 1 11 2 12
Insérer une colonne
Dans l'exemple suivant, la méthode insert permet d'insérer la colonne genre à l'index 1
-
>>> df.insert(loc=1, column='genre', value=['M', 'F', 'M']) >>> dfage genre 0 12 M 1 11 F 2 12 M
Analyse
Fonctions et méthodes d'aide à l'analyse des données
Tableau croisé
Dans l'exemple suivant, la méthode crosstab permet de créer un tableau croisé dynamique avec la fréquence des différents genres pour chaque groupe d'âge sous la forme d'un dataframe.
-
>>> pd.crosstab(index=df['age'], columns=df['genre'])genre F M age 11 1 0 12 0 2
Graphiques
Représentations des données à l'aide de diagrammes
Histogrammes
A l'aide de la méthode hist de la bibliothèqe matplotlib pyplot.
Seules les colonnes contenant des données numériques sont représentées.
-
>>> df.hist() array([[<Axes: title={'center': 'age'}>]], dtype=object)
Matrice de graphiques de dispersion et d'histogrammes
Pour chaque paire de variables numériques du dataframe à l'aide de la méthode pairplot de la bibliothèqe seaborn
-
>>> sns.pairplot(df_csv) >>> sns.pairplot(df_csv, hue="RF")
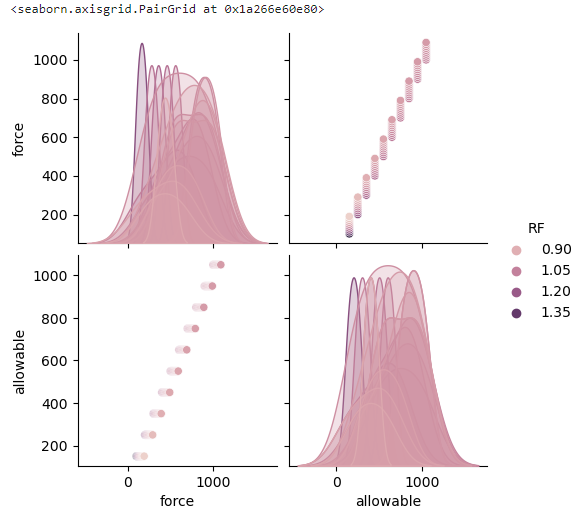
Graphique de dispersion
A l'aide de la méthode scatterplot de la bibliothèqe seaborn
-
>>> sns.scatterplot(df_csv, x="force", y="RF")